For every language, a small exception dictionary containing difficult words and their phonetic representation is available. A lexical entry has a HPSG-like representation. A new word is added to the dictionary after a test (the phonetic form is generated by using the set of constraints, and this form is compared with the phonetic representation associated with the word).
The system can work in two ways:
- a word from the dictionary is pronounced according to its corresponding orthographic representation;
- a new word can be pronounced after the language has been specified and the corresponding orthographic form has been generated according to the set of constraints.
A collection of phonemes is available, being stored in f-structures of the types introduced before. To improve the pronunciation, some techniques for modifying speech parameters like intonation and rhythm [5,6,7] are also described by using the formalism.
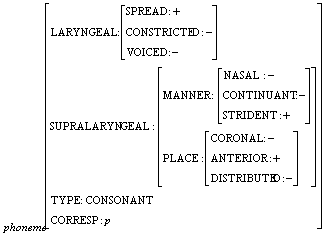
Example: Most part of the consonants in Romanian and English languages are described in the same way, using the representations introduced with the model.
English: p is a bilabial, fortis, voiceless, plosive consonant;
Romanian: p is a labial, voiceless, occlusive consonant.
The representation given below is a good description of the phoneme and covers the descriptions given in both languages:
The steps necessary to be followed in order to obtain speech synthesis from the initial text are:
- the transformation from text to orthographic string, using context-dependencies rules;
- accent identification, after the correct identification of the syllables;
- application of rhythm and intonation rules, in order to improve the pronunciation.
The constraints specific to each language are divided into three sets:
- constraints imposed by the context (context-dependencies rules);
- accent identification rules (depending on the four suprasegmental phonemes existing in each language);
- rhythm and intonation rules (which are used in the case of continuous speech).
171


