Marian Boldea * Speech Technology Research at Computer Science Department, "Politehnica" University of Timiºoara
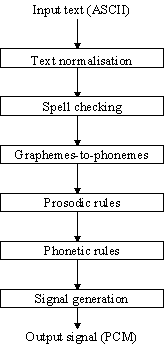
Fig. 1. - Block diagram of the text-to-speech system.
A first set of experiments have explored their use
in isolated word recognition [3]
and tried to select an optimal
signal processing method [4].
Using a database of 0 to 9 digits
[5] spoken by 100 speakers,
balanced by sex and split into a 68-speaker
training test and a 32-speaker test set, recognition scores higher
than 99% have been achieved [4].
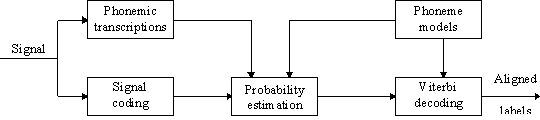
At present, continuous speech recognition is investigated
by using an appropriate database [10]
to be first automatically
labelled at the phoneme level. This will be realised by using
a simplified version of an automatic continuous speech recognition
system [16] (Fig. 2).
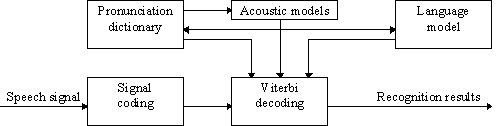
Once labelled, the database will be used to train
acoustic models for a speaker- independent continuous speech recognizer
(Fig. 3), which essentially is a directed Viterbi decoder that
evaluates the probabilities of various word sequences as the likelihoods
of the analysed signal being generated by the sequence of acoustic
models associated to their pronunciations, with a pruning procedure
used to reduce the computational load and processing time
[17].
Fig. 2. - Block diagram of the automatic labelling system.
Fig. 3. - Block
diagram of the automatic continuous speech recognition system.
As far as our work is concerned, at one point or
another we have felt the need for all these, and we hope that
the future will bring some changes without which there is little
to be expected.
176
5. Instead of conclusions


