We may take into account two main applications of speech synthesis [3]:
A. The synthesis of messages made up of previously established isolated words or sentences
The typical applications are the public announcement systems and the transmission of standard messages by phone. The utilised vocabulary is small enough, word or sentences being processed once and then memorised. Despite the actual low price of memory circuits, it must be observed that a second of speech requires 64-128 kb for a simple PCM coding and 2.4 kb if one uses linear prediction coding (LPC). The essential issues of these systems are naturalness of words or word group concatenation and a certain phrase intonation.
B. The automatic conversion of stored text to synthetic speech (Text-to-Speech)
Terminal based applications of TTS technology include talking terminals and training devices, warning and alarm systems, talking aids for the hearing-impaired and vocally handicapped and reading aids for the blind people. Audiotext services allow users to retrieve information from public or private database using a telephone as a terminal. While some of this information could be provided using stored human speech, TTS systems are appropriate when services access a large or frequently changing database. TTS systems reduce also storage needs to a few hundred bits for an equivalent text sentence.
The vocabulary is theoretically unlimited and speech must be as much as possible fluent, intelligible and natural. An appropriate number of segmental synthesis symbols must be found for the synthesis of unrestricted text.
Following the features and historical evolution of the applications listed above, automatic speech synthesis methods are generally divided into three types:
- Synthesis based on waveform coding (or direct synthesis), in which speech waves of recorded human voice, stored after waveform coding, are used to produce desired messages.
- Synthesis based on the analysis-synthesis method, in which speech waves of recorded human voice are transformed into parameter sequences by the analysis method and stored, with a speech synthesizer being driven by concatenated parameters to produce messages.
- Segmental synthesis-by-rules, in which speech is produced by phonetic and linguistic rules from letter sequences or sequences of phoneme symbols and prosodic features.
The principles of these three methods are presented in Figure 1 and a few details of each method will be discussed in the following.
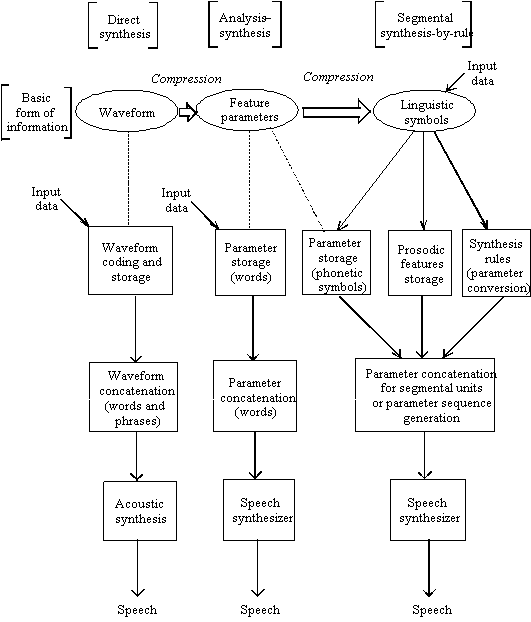
Fig. 1. - Basic
principles of three speech synthesis methods.
140


