Corneliu Burileanu & al * Text-to-SpeechSynthesis for Romanian Language
We must however emphasise here that one must avoid the confusion between two concepts of a text-to-speech system; we shall then define:
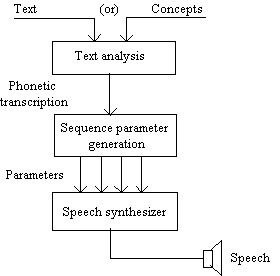
For a TTS system this difference is shown in Figure 2.
Fig. 2. - Text-to-speech system principle.
For a text-to-speech system, the speech synthesizer usually uses either a formant-based synthesis technique, or linear prediction analysis and synthesis techniques. They will be also discussed in the next chapter, together with a description of a rather new technique for speech synthesis: the pitch-synchronous overlap-add (PSOLA) technique.
We will only observe at this moment that another synthesis technique being developed for experimental TTS system is articulatory synthesis. This technique represents phonemes as articulatory targets and employs rules that model how articulators move in time and space to generate connected speech. Articulatory control parameters rather than text input or acoustic parameters control these synthesizers. It is hoped that the articulatory approach will lead to simpler and more elegant rules that will model more closely the human speech; however, a lack of complete, detailed articulatory data, makes difficult the optimization of articulatory TTS systems.
Text-to-speech systems can be
evaluated and compared with respect to intelligibility, naturalness
and suitability for particular applications. One can measure the
intelligibility of individual phonemes, words, or words in sentence
context and one also estimates listening comprehension of synthetic
speech. But what is even more important in conceiving such a system
is the predicted performance for a specific application; there
is no existent TTS system good enough to fully replace a human,
but it can be perfectly acceptable if it is part of an application
that provides direct access to information stored in a computer,
or permits easier or cheaper access to a present service because
more telephone lines can be handled at a give cost, or can help
blind persons to have full access at their computers (eventually
connected on a large network).
What we want to suggest is the
fact that even for Romanian language, the design of a TTS system,
which is obvious a very difficult task and must involve the most
diverse interdisciplinary efforts, needs to be oriented to a
specific application.
142


