Corneliu Burileanu & al * Text-to-SpeechSynthesis for Romanian Language
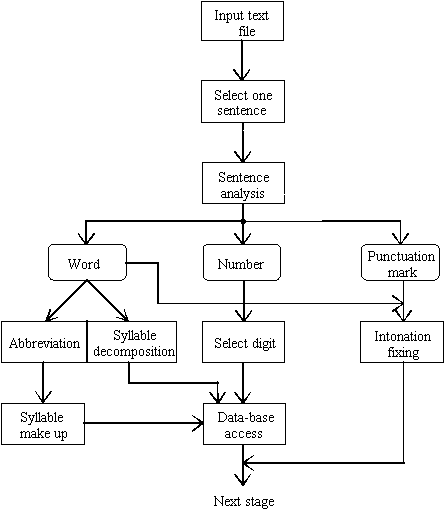
The format analysis for the input text in our system is presented in Figure 5.
Each sentence from the input text is divided in words and numbers, following the basic punctuation marks; according to these punctuation marks, an intonation type is also associated with some words.
Then, the words are syllable decomposed; for the words made up of single letter abbreviations (like in S.R.L.), we attach to each consonant the "e" vowel so that one obtains distinct syllables.
Numbers are digit decomposed and receive their complete name and the corresponding punctuation (for example, 123.21 becomes o-sutã-douã-zeci-ºi-trei-virgulã-douã-zeci-ºi-unu). All words needed for numbers make up are considered "reserved words" and stored in the data base.
Fig. 5. - The text processing algorithm.
4.2.6. The speech synthesis stage
As mentioned, the system is able to concatenate either the stored syllable waveforms or the LPC parameters for a LPC driven speech synthesizer. Although the data-base of LPC parameters is not entirely ready at present, a powerful LPC speech synthesizer is already implemented, with the following performances: 2.4kb/s compression rate, real-time synthesis, good intelligibility and naturalness. The encoding of the analysis parameters (the predictor coefficients, the pitch period, a voiced/unvoiced parameter and the gain) was made using the "LPC-10" standard [16].
The speech synthesis from the linear predictive analysis parameters is done with a system that is similar to that used in the analysis. An impulse generator is the excitation source for voiced sounds (with a pulse at the beginning of each pitch period). A white noise generator is the excitation source for unvoiced sounds. The selection between the two sources is made by the voiced/unvoiced parameter. The gain determinates the amplitude of the excitation. The speech samples are obtained as the response of the network digital filter with the predictor coefficients, as parameters. The synthesis time is less than 10% of the real time in which the synthetic speech is "spoken" (on a 486 equipped PC at 66 MHz).
Intensive studies are also made
at present for determining the prosody of spoken utterances in
Romanian language, especially intonation and stress
[17, 18]. The intonation pattern is defined to
be the pitch pattern
over time for a spoken sentence; the stress pattern on syllables
can distinguish two words even if they have identical segmantal
phonemes. It is known that fundamental frequency affects both
intonation and stress and it is obvious that the pitch contour
is fundamental for the intelligibility and naturalness of the
speech synthesis system.
148


