Mihai Ciocoiu, Ştefan Bruda * GULiveR: Generalized Unification Based LR Parser for Natural Languages
For grammars which are not LR, the parse table will have multiple action entries, corresponding to the shift/reduce and reduce/reduce conflicts. Tomita's algorithm operates by maintaining a number of parsing processes in parallel, each one behaving basically as a standard LR parser. All the parsing processes share a common graph-structured stack, the key structure for the efficiency of the algorithm.
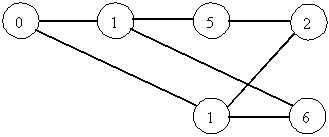
Fig. 2. - Example graph-structured stack.
The root (node 0 in the figure above) acts as a common bottom of the stack for all the processes. Each vertex of the graph represents an element (a parse state) in some of the stacks merged in the structure and each leaf of the graph corresponds to an active parsing process, and acts as its top of stack.
All processes are synchronized and behave in the following manner. On each input token, each process acts like a standard LR parser, guided by the parse table. When a process encounters a conflict in the parse table, it splits into several processes, one for every action. When two or more processes are in the same state (have the same state in their top of stack), they will exhibit the same behavior until the state is popped by some reduce action. To avoid this repetition, those processes are unified into a single one, by merging their stacks. When a process executes a reduce action, all the nodes between its top of stack and the ancestor corresponding to the first symbol of the production must be popped. Since a vertex may have multiple parents, some reduce actions can be done on several paths in the graph-structured stack. When this happens, the process is again split into separate processes. The algorithm begins with a single initial process and follows the procedure above until all processes die, which signifies rejection, or until a process reaches an acceptance state.
The parse trees generated by the different processes are also merged in a packed shared parse forest. Sharing refers to the fact that if several trees have a common sub-tree, the sub-tree is represented only once in the forest, and packing refers to the fact that the top vertices of sub-trees that represent local ambiguity are merged and treated as if there were only one vertex.
Since each step in the parsing process operates only on the two most recent stages, in the parser implementation we will need direct access only to them. In our encoding they will be current-stack and next-stack.
Also, since the shift actions and the reduce actions are considered at different places in the parse process, separating the tops of stack with reduce actions from those with shift actions has proven to be useful. All the tops of stack with shift actions are held in shift-stack, and all having reduce actions are held in reduce-stack. A stack top with both shift and reduce actions will be present in both structures. The data structure description (biased towards the LISP implementation) is:
current-stack ::= step-stack next-stack ::= step-stack step-stack ::= (reduce-stack . shift-stack) shift-stack ::= (shift-head ...) reduce-stack ::= (reduce-head ...) shift-head ::= (branch . shift-list) reduce-head ::= (branch . reduce-list) shift-list ::= (shift-structure ...) reduce-list ::= (reduce-structure ...) shift-structure ::= (action . lex-dag) reduce-structure ::= (action lex-pair ...) lex-pair ::= (lex-dag term-code ...) branch ::= (node . link) node ::= state | dag link ::= branch | branch-list branch-list ::= (branch ...)
where lex-dag is the dictionary entry for a lexical graph.
96


