Mihai Ciocoiu, Ştefan Bruda * GULiveR: Generalized Unification Based LR Parser for Natural Languages
Masaru Tomita published his algorithm for monadic grammars [10]. In [14] together with the extension of the LR Parse Table construction algorithm, some observations are made about the changes that must be made to the LR algorithm for unification-based grammars. These changes also apply to Tomita's algorithm.
When applied to monadic grammars, there is no need for verifying the categorial correspondence during parse time. In this case, the categories are placed in the stack only for constructing a parse tree, and reduce actions are independent of the categories in the stack. This is no longer true for unification-based grammars.
For unification-based grammars, the parser must unify a categorial graph with the corresponding sub-graph from the right hand side of the productions, during the reduce actions. For efficiency reasons, a shallow copy of the rule and its subgraphs is created at the start of the reduce action. This means that when a reduce action starts, the rule's environment is shallow (pointer-level) copied. Since the sub-graph environments are pointers to the graph environment, upon finishing the reduce action the left hand side of the rule will have new semantic information as a result of the unification operations done with its right-hand subgraphs.
A small improvement can be done by carefully selecting the order of the unification operations, since the categorial graph usually has a small environment, while the rule's environment can be quite large.
This project started as the Generalized LR parser described in [15], which worked on PCs under Golden Common Lisp. We extended it for unification-based grammars and moved it to Mac Common Lisp, with the purpose of integrating it into the PAIL [16] system. PAIL already contains a chart-parser for structured categories, a typical parsing algorithm for natural language processing. We believe that the presence of two different parsing methods offers an interesting comparison between two main paradigms (chart-based and table-driven algorithms).
The application does not offer a grammar preprocessor. The grammar must be introduced as a Lisp form, which may be a laborious work for a large grammar. We plan to develop such a preprocessor.
On the complexity point of view, we do not have any formal expression for the time of execution. We believe that such expression can be found starting from the time complexity of Tomita's algorithm (O(np), where p is the length of the longest production) and time complexity of unification. From experimental data we found that the unification (including the unifications required for lexical look-up) requires a time at least double than that of effective parsing.
Note that [10], if a unification-based grammar for a natural language has only 50 - 100 productions, the number of productions for a monadic context free grammar for the same language is of 103 order. Thus the supplementary time required for the unification processes is justified.
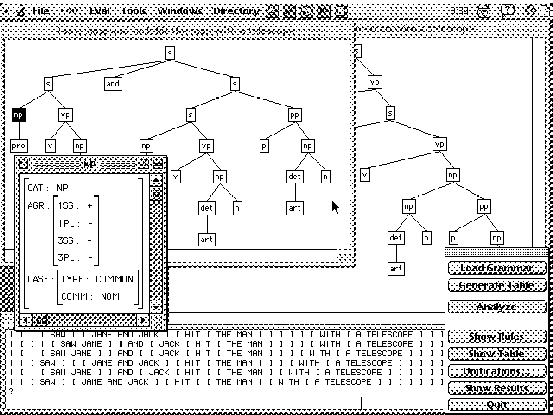
Fig. 5. - The resulting parse trees.
103


