Mircea Giurgiu *
Results on Automatic Speech Recognition in Romanian
2.3. Vector quantization for bit-rate reduction
A vector quantizer is a system
for mapping a sequence of continuous or discrete vectors into
a digital sequence suitable for communication over or storage
in a digital channel. The goal of such a system is data compression.
In the past few years several algorithms have been designed for
VQ and their performance has been studied for speech wave.
A k-dimensional
memoryless VQ consists in two mappings: (a) an encoder,
which assigns to each input vector
X=[x(0), x(1),...,x(k-1)]
a channel symbol 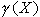 in
the symbol channel set: {Y(i); i=1,2,...,M},
and (b) a decoder
in
the symbol channel set: {Y(i); i=1,2,...,M},
and (b) a decoder 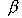 ,
which assigns to
each channel symbol "v" a value in the reproduction
alphabet A [1,6,7].
To set up a VQ system means to realize a partition
in the set of all vectors X in classes Ci.
In each of them it distinguishes a particular vector Yi
called a prototype or "centroid". Each vector X
in Ci will be represented by his prototype
Yi.
All set of Yi realize a codebook (Fig. 5). Substituting
X with Y realizes a distortion d(X, Y).
,
which assigns to
each channel symbol "v" a value in the reproduction
alphabet A [1,6,7].
To set up a VQ system means to realize a partition
in the set of all vectors X in classes Ci.
In each of them it distinguishes a particular vector Yi
called a prototype or "centroid". Each vector X
in Ci will be represented by his prototype
Yi.
All set of Yi realize a codebook (Fig. 5). Substituting
X with Y realizes a distortion d(X, Y).
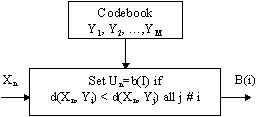
Fig. 5. -Vector Quantization principle.
The most important problem in
VQ is the design of C from a set T of training
vectors. Two sets of experiments have been designed by using Linde-Buzo-Gray
(LBG) algorithm [7]
SET1: 6613 vectors collected from 1 speaker uttering 10 times the 10 digits (Table 1)
SET2: 6613 vectors collected from 3 speakers uttering 3 times the 10 digits (Table 2)
and we generated vector quantizers of size M =2, 4, 8,
16, 32, 64, and 128. During the course of running the algorithms
(Fig. 6-9), several performance criteria were monitored including:
(a) average distortion (SNR versus number of iterations); (b)
cluster separation of the resulting coding entries; (c) cluster
cardinality (number of tokens in each cluster); (d) cluster distortion;
(e) SNR in the encoding process (after VQ training)
[3].
Table1. VQ performances for SET1
| VQ size M
| SNR Training [dB]
| Cluster Cardinality
| SNR Coding [dB]
|
| 32
| 24.9
| 209.35
| 23.35
|
| 64
| 26.4
| 104.07
| 26.88
|
| 128
| 27.8
| 51.82
| 28.25
|
Table 2. VQ performances for SET2
| VQ size M
| SNR Training [dB]
| Cluster Cardinality
| SNR Coding [dB]
|
| 32
| 24.9
| 225.06
| 25.27
|
| 64
| 26.2
| 111.92
| 26.56
|
| 128
| 27.5
| 55.90
| 27.91
|
Table 3. SNR versus the VQ size (M) for the
word /unu/ ("one") - SET1
| VQ size M
| SNR Coding [dB]
|
| 32
| 24.33
|
| 64
| 25.40
|
| 128
| 26.70
|
The conclusion we found for VQ
is that it is a powerful tool in speech processing: it produces
a high compression rate and reduces the amount of computation
in the ASR process. The technique has been applied for isolated
word recognition using DTW and also with HMM. For values of M
greater than 32 the distortion error does not decrease very much,
so we select M=64 in our approaches. The larger cluster
has 362 tokens, whereas the smaller cluster has 62; hence, a spread
of over 7 to 1 in cluster occupancy is obtained. The average cluster
cardinality is 225 (for the case M=32) and the histogram
of cluster cardinality indicates that the vast majority of clusters
have fewer than the average number of tokens. A spread of more
than 6 to 1 was also observed for cluster distortion
[3].
180


