Table 4. The recognition percentage for VQDTW multilocutor experiment
| Word | Recognized (M=32) | Nonrecognized (M=32) | Percent (%) | Recognized(M=64) | Nonrecognized (M=64) | Percent (%) |
| "Unu" | 15 | 0 | 100 | 15 | 0 | 100 |
| "Doi" | 13 | 2 | 86.66 | 13 | 2 | 86.66 |
| "Trei" | 15 | 0 | 100 | 14 | 1 | 93.33 |
| "Patru" | 15 | 0 | 100 | 15 | 0 | 100 |
| "Cinci" | 15 | 0 | 100 | 15 | 0 | 100 |
| "ªase" | 13 | 2 | 86.66 | 14 | 1 | 93.33 |
| "ªapte" | 13 | 2 | 86.66 | 14 | 1 | 93.33 |
| "Opt" | 11 | 4 | 73.33 | 12 | 3 | 80 |
| "Nouã" | 15 | 0 | 100 | 15 | 0 | 100 |
| "Zece" | 15 | 0 | 100 | 15 | 0 | 100 |
| Total | 140 | 10 | 93.33 | 142 | 8 | 94.66 |
From the VQDTW-type of experiments we have concluded that the recognition performance depends on the VQ size M (32 and 64) being 94%, respectively 96%, for monolocutor experiments and 93.33% and 94.66% for multilocutor experiments. Even though the recognition rate is poorer for VQDTW than for DTW, the advantages consist in the memory size and computing speed, so a possibility to implement the algorithms on DSP platforms arouses.
3.2. Hidden Markov Models applied for automatic recognition of Romanian digits
A HMM is a model of speech generation,
although it is used for speech recognition purposes. It is characterized
by five elements: (a) A state set S with N states
S={s1,s2,...,sN}.
Denote the current state at time t as qt. (b)
A symbol set with M different symbols
V={v1,...,vM}.
Current symbol at t, Ot. (c) A transition
probability distribution A={aij}, where
aij is the transition probability from state
si to state sj. (d) A symbol
probability distribution B={bj(k)}, where
bj(k) is the production probability of symbol
vk at state sj. (e) An initial
state distribution 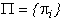 (probability that
the symbol generation begins in state si).
(probability that
the symbol generation begins in state si).
For a vocabulary with L
words {W1, W2,...,WL},
the recognition system is a set with L HMM
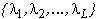 ,
where each model
,
where each model 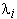 is associated with one
word Wi of the vocabulary. Given an input symbol
sequence, the generation probability
is associated with one
word Wi of the vocabulary. Given an input symbol
sequence, the generation probability
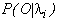 is computed for every model
is computed for every model 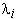 .
The model
giving the highest probability corresponds to the recognized word.
For speech recognition, it is suitable to use the left-to-right
model, because it matches the sequential nature of the speech
generation process [8].
.
The model
giving the highest probability corresponds to the recognized word.
For speech recognition, it is suitable to use the left-to-right
model, because it matches the sequential nature of the speech
generation process [8].
The vocabulary consists of the ten Romanian digits recorded under normal conditions of work room with computer noise at 10 kHz and 16 bits/sample. LPC analysis has been applied and then VQ with the codebook size M=64. We have recorded a large number of speakers (40) uttering 3 times each word, but this communication presents only two subsets of this large database. One is for training the HMM and is composed of 3 speakers, and the other contains the testing subjects, totally independent from the first one. Ten HMM have been designed for each word. During the training step, the number of states (N) of HMM was variable, in order to detect which is the best number of states. Theoretically, the larger N is, the better the results should be. This is not always true, and an N greater than 6 does not much improve the performances (Fig. 10). Since the Romanian speech database was too small, the HMM were verified with a Spanish database obtained from Granada University. The results were similar and they demonstrated the validity of our results [3,8].
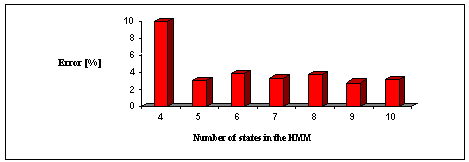
Fig. 10. - The recognition error versus the number of states in HMM.
182


