Each of the two signals used in application, the master and the student one, is object to a pre-processing phase that intends to prepare it for comparison. The pre-processing phase includes loudness computing, silence detection, ZCR computing, fricatives' detection, noise elimination, pitch determination, prosody computing.
Figure 1 is illustrative for the pre-processing chain and for the interactions among processes. For instance, pitch detection is correlated to the output of silence detection and fricatives' detection, the segmentation's output is a list of labelled segment markers that, in turn, is input to two alternative processes: signal editing and signal-to-text alignment. The dotted line between pitch detection and signal-to-text alignment suggests that the latter is correlated to voiced/unvoiced decision taken in the former. Each step in pre-processing phase is described below.
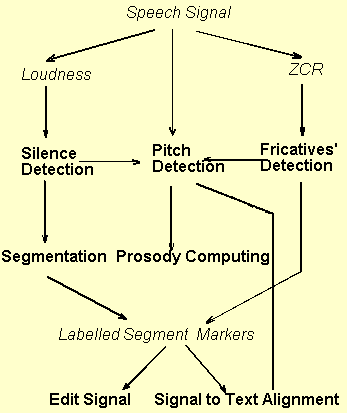
Fig. 1. - Pre-processing applied to a signal in PROSODICS (up to the comparison phase).
3.1. Loudness
The signal's loudness is represented by means of a data structure that bears a measure of the energy of the signal on delimited frames, the amplitude maximum and minimum of the signal inside each frame, as well as the signal's global maximum and minimum of energy. The loudness is obtained by analyzing the original signal using frames of 10 ms, a "go-ahead" step of 5 ms, with the same sample frequency as the original sound. If that N is the number of samples corresponding to 10 ms, S represents the original signal data and ZERO the value related to which the signal is changing the sign, the values in the loudness are obtained according to the formula:
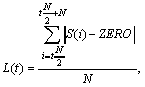
for 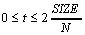 ,
SIZE being the signal length in number of samples.
The frames moving along the signal are half-overloaded. The length
of the frame we chose to build loudness is rather small, fineness
needed to reflect a better approximation of the original sound;
this accurate time resolution will permit to leave the signal
domain when detecting silence and segmenting, and to use only
the loudness, thus saving computational time. See figure 7 - (c)
as an illustration of the loudness function.
,
SIZE being the signal length in number of samples.
The frames moving along the signal are half-overloaded. The length
of the frame we chose to build loudness is rather small, fineness
needed to reflect a better approximation of the original sound;
this accurate time resolution will permit to leave the signal
domain when detecting silence and segmenting, and to use only
the loudness, thus saving computational time. See figure 7 - (c)
as an illustration of the loudness function.
153


