Maria-Mirela Petrea, Dan Cristea * Dealingwith Prosody. A Computer-Assisted Language Learning Approach
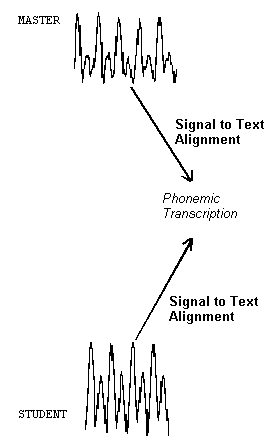
Signal-to-text alignment results in a segmentation at phoneme-group level. The alignment markers computed are labelled with the phoneme group they delimit inside a signal. This phase is obviously language dependent; however, this is not a limit of PROSODICS.
Fig. 9. - Signal-to-Text alignment.
The signal-to-text alignment module is dependent on what we called a "feature table", that is a list with phonemes and a static description of them by means of class affiliation (vowel, nasal, stop, etc.), voiced/unvoiced, energy level, zero-crossing level, expected duration. Until now we used only the Arpabet for English, but to write a table alike for any other language and to transmit it as a parameter to the program, it is an easy task. The algorithm's input is constituted by a phonemic transcription and the segmentation phase result, i.e. a list with labelled segment markers. It tries to select among them those markers best fitting to a description of a phonemes group in the feature table. It uses also a branch-and-bound method to search and select in the state space. A node in the space points primarily to a segment and to a phoneme, or a sequence of phonemes, in transcription. At a certain moment, the space's growing may be interrupted by a silence segment, by the impossibility to concatenate two segments, by an inconsistency in the space, like when trying to match a nonfricative marked segment against a fricative-phoneme. Each path is given a penalty score according to the distance between the phonemes' description it assumes it covers and the features actually residing in the signal, and the path with the greatest score is chosen to continue the search.
Usually, a phoneme-like alignment is performed, where the signal contains sequences of significantly different phonemes. It groups altogether more than one phoneme when they have similar properties; for instance, when uttering "decorative", with the phonemic transcription "d eh k ax r ax t ih v", a unique marker with "ax r ax" label will result, since these phonemes have similar descriptions in the table, and the signal is not significantly varying when they are pronounced (see figure 10).

Fig. 10. - Signal-to-phonemes
alignment for "decorative".
159


