Amalia Todiraºcu *
A Unification-Based Model for Speech Generation
The treatment of the morphological,
syntactic and semantic features in the same manner can be illustrated
by an example taken from morphology, where the affix and the root
of the word are combined together into a single expression.
Example:

The verb sees is represented
by the next structure:

The root of the verb and the affix
are objects in the list which is the value of the attribute DTRS.
2. A model for speech generation
The second part shortly describes
a general model for speech generation. The model is based on typed
feature structures, defining a hierarchy of types. The basic operations
with the structures will be the unification and subsumption. The
rule representations are replaced by descriptions of the objects
and of the constraints to be satisfied. Prosodic domains, which
limit the applicability of phonological constraints, are expressed
in a prosodic-type hierarchy modelled in the HPSG style. The collection
of feature structures describing the phonemes will be used for
generation. Some additional information, like the place where
the sound is produced, or the manner in which it is pronounced,
is also stored in the structures.
The new types for describing the
phonological data are:
phon = list(foot)
foot = list(syl)

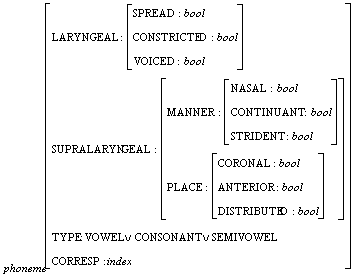
where
phon is used to describe an utterance;
foot is used to describe a word;
syl is used to describe the structure of a syllable;
phoneme describes the features of each phoneme.
A syllable (syl) has three
attributes CONS, VOC, SEMIVOC (each of them being lists of objects
of type phoneme) and an attribute SKEL, which gives the
real order of the phonemes in the word (or in the syllable). This
attribute can be viewed as the attribute SUBCAT from the syntactic
features.
168


