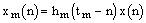
Corneliu Burileanu & al * Text-to-SpeechSynthesis for Romanian Language
This synthesis method uses pieces of natural speech (usually encoded) as building blocks to reconstruct an arbitrary utterance. The principle of this method is to store parameters that characterize acoustical units or transitions between them, rather than to model these units (as the previous method does) [6].
Concatenative synthesis methods use various representation of units of speech that are concatenated together to form connected speech; these representations indicate at the same time the techniques used by the speech synthesizers. Two important techniques are used today:
The TD-PSOLA synthesis scheme involves the three following steps: an analysis of the original speech waveform to produce an intermediate non-parametric reprezentation of the signal, prosodic modification brought to this intermediate reprezentation and finally the synthesis of the modified signal from the modified intermediate representation. We present here the basic feature of this algorithm.
The waveform x(n) is decomposed into a sequence of short-term overlapping signal xm(n). This short-term signal is obtained by multiplying the signal by a sequence of analysis windows hm(n):
The successive instants tm, called pitch-marks, are set at a pitch-synchronous rate of the voiced portions of the signal and at a constant rate on the unvoiced portions.
The stream of analysis short-term
signal is processed to produce a stream of modified synthesis
short-term signal 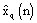 ,
synchronized on a
new set of synthesis pitch-marks fq. The algorithm
determines simultaneously the synthesis pitch-marks according
to the pitch-scale and time-scale modification factors and the
mapping between the synthesis and analysis pitch-marks. This mapping
specifies which analysis short-term signal is to be copied to
obtain any given synthesis short-term signal; the stream of synthesis
pitch-marks indicates the delay to be used in the synthesis short-term
signal.
,
synchronized on a
new set of synthesis pitch-marks fq. The algorithm
determines simultaneously the synthesis pitch-marks according
to the pitch-scale and time-scale modification factors and the
mapping between the synthesis and analysis pitch-marks. This mapping
specifies which analysis short-term signal is to be copied to
obtain any given synthesis short-term signal; the stream of synthesis
pitch-marks indicates the delay to be used in the synthesis short-term
signal.
Generally, this mapping is not one-to-one and results in either a duplication or an elimination of the analysis short-term signal. The synthetic speech x(n) is obtained by overlap-adding the stream of synthesis short-term signal:
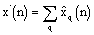 .
.
Because the synthesis process is syncronized with the pitch synthesis period, the algorithm controls simultaneously the value of the synthesized pitch and the duration of the synthesized signal.
This algorithm is an efficient method to modify the prosodic parameters, while preserving most of the naturalness of the voice timbre. Moreover, it can be combined in a flexible manner with low-bit rate speech coding in order to reduce the memory requirements to store the acoustical units inventory.
In recent years, a lot of work
was done in achieving text-to-speech synthesis for Romanian language.
It must be first mentioned that the basic features of the synthesis
at the research start were intended to be the following:
We will discuss two different
approaches for this task.
145


