Corneliu Burileanu & al * Text-to-SpeechSynthesis for Romanian Language
We are currently developing a modular software TTS system, based on diphone concatenation and a neural approach. Because work on this topic was presented elsewhere [13], we will only give here a brief description.
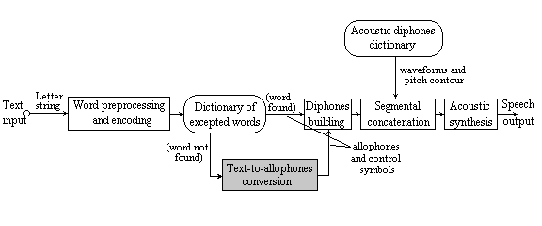
The main structure of the system is shown in Figure 4.
Fig. 4. - Text-to-speech system based on diphone concatenation.
The word preprocessor realizes a normalization of the input letter strings (detects special symbols, cancels the distinction between lowercase and uppercase, cancels also hyphens and some punctuation marks) and encodes each letter and the symbol "space" with five bits. Then the word passes through an exceptions dictionary (comprising about 180 words with many pronouncing problems, such as word with some diphthongs at the beginning or at the end of them, or with graphemes having two corresponding phonemes). If the word is found then the dictionary produces its phonetical transcription; if not, it passes through a neural network module (based on a Multi-Layer Perceptron trained by error back-propagation) and one obtains the phonetical transcription (a sequence of allophones and control symbols: "" - the phonetic zero unit - for aligning the orthographic and phonemic representation for some letter groups and a special symbol ("!") for the primary stress, before the corresponding vowel). The allophones are then simply grouped by two (for example, the word semnal - "signal": #s, se, em,mn, na, al, l#). Using an inventory of stored and labelled diphones units, the segments are finally concatenated with a modified overlap-and-add algorithm.
We are also working on a different approach for a text-to-speech synthesis: a system based on syllable concatenation, either in their stored form, or using a LPC-based speech synthesizer. This approach will be presented in more details.
4.2. A text-to-speech system based on syllables concatenation
4.2.1. Principles and requirements
A syllable-based speech synthesis technique requires first an acoustic inventory of stored and digital processed syllables; after a LPC analyses, their corresponding LPC parameters are also stored and labeled. In our system, the input text in Romanian language is first analyzed in terms of punctuation marks and then automatic decomposed into syllables. These obtained units are either matched with their correspondents from the acoustic inventory and directly concatenated, or connected using the LPC stored parameters and a determined prosody contour.
This synthesis approach asks the following important steps:
146


