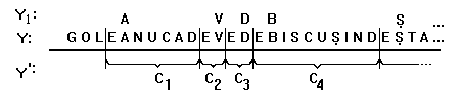- Λ-arbitrarily (according to case) chosen interval;
- s letters - the method parameter;
- ΛG - search zone for the first reoccurrence of letter G;
- ΛO - search zone for the first reoccurrence of letter O;
- Y - first-order Markov chain: GOL...
- s letters - the method parameter;
In order to have an idea about how these sequences look like we
present the first 50 characters of the Y text considered in our
analysis for printed Romanian:
GOLEANUCADEVEDEBISCUªINDEªTADUTSADOSEROGARULADOPAR
(in text without blanks).
Our method continues with the
choice of a letter from the Romanian alphabet, that we shall call
marker-letter, or simply marker:
let it be, for example, letter E.
We now transform the texts generated
by source Y into sequences of conventional words (artificial,
meaningless words), all beginning with the same letter E (the
marker-letter) as shown in Fig. 2:
In this way, a new information
source Y' comes out, having as symbols conventional words
of Ck type (letter E appears in each conventional word
only once, at the beginning).
According to Theorem 2.11 (W. Doeblin), [5],
the new information source Y' is a stationary zero-memory source.
Further we obtain one more information
source Y1, by recording only the letter following after
the marker in the Y source texts. For example, in Fig. 2 we obtain
the following sequence belonging to Y1: AVDB... .
On the basis of the above-mentioned
Doeblin Theorem, it can be shown that Y1 is a stationary,
zero-memory source having the same alphabet as X source, but different
letter probabilities. Namely, these probabilities give exactly
the information we are looking for in NWL, i.e. the conditional
probabilities based on a single preceding letter which is the
marker (see the Proof at the end of this section):
pY1
(j) = pY(j/E) =
pX(j/E).
In relation (1) the subscript
letters stand for the information sources Y1, Y or
X; j is an arbitrarily chosen letter from the NWL
and E is the marker.
We can obviously choose any other
letter i of the alphabet instead of E as marker-letter,
and consequently we can determine the whole set of transition
probabilities of the type pX(j/i).
In order to estimate the pX(i,j)
digram probabilities in NWL we
first have to determine the pX(i)
letter occurrence probabilities:
pX(i,j) = pX(j/i) .
pX(i).
45